This is the translation. The original web-page (oryginalna strona): https://userweb.ucs.louisiana.edu/~isb9112/dept/phil341/wisconn.html
István S. N. Berkeley Doktorat
Koneksjonizm to styl modelowania oparte na sieciach połączonych prostych urządzeń przetwórczych. Ten styl modelowania przechodzi przez szereg innych nazw zbyt. Modele koneksjonistyczne są czasami określane jako „Równoległe przetwarzanie rozproszone” (lub w skrócie) PDP modeli lub sieci.1 Systemy koneksjonistyczne są czasami określane jako „sieci neuronowych” (w skrócie NN) lub sztucznych sieci neuronowych” (w skrócie ANN). Chociaż mogą być pewne retoryczne odwołanie do tej nomenklatury nerwowej, w rzeczywistości jest mylące, ponieważ sieci koneksjonistyczne są zwykle znacząco niepodobne do systemów neurologicznych. Z tego powodu, będę unikać używania tej terminologii, inny niż w bezpośrednich cytatów. Zamiast tego, będę stosować praktykę przyjętą mam powyżej i używać „koneksjonistyczne” jako mój podstawowy termin dla systemów tego rodzaju.
Podstawowe elementy systemu łącznikowego są następujące;
- Zestaw jednostek przetwarzania
- Zestaw modyfikowalnych połączeń między jednostkami
- Procedura uczenia się (opcjonalnie)
Po kolei opiszę każdy z tych elementów. Czytelnicy, którzy wymagają dalszych szczegółów technicznych, powinni zapoznać się z ogólnymi ramami dla systemów łącznikowych opisanych przez Rumelharta, Hintona i McClellanda (1987).
Jednostki przetwarzania
Jednostki przetwarzające są podstawowymi elementami konstrukcyjnymi, z których zbudowane są systemy łącznikowe. Jednostki te są odpowiedzialne za wykonywanie przetwarzania, które odbywa się w sieci połączeniowej. Dokładne szczegóły przetwarzania, które zachodzą w danej jednostce, zależą od funkcjonalnych podskładników jednostki. Istnieją trzy kluczowe podskładniki. To są,
- a) siatka2 funkcja wejściowa
- b) aktywacja funkcji
- c) funkcja wyjściowa
Różne komponenty jednostki przetwarzania można przedstawić w następujący sposób:
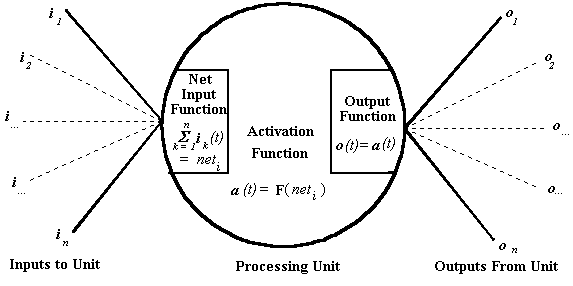
Rysunek 3-1
Funkcji wejścia netto jednostki przetwarzania określa całkowity sygnał, że dany zespół odbierający. Funkcja wejścia sieci przyjmuje jako dane wejściowe sygnał, który przyjmuje jednostkę ze wszystkich źródeł (ii-m), włącznie z innymi jednostkami, który jest połączony. Często zdarza się, że funkcja wejścia netto jednostki jest stosunkowo prosta. Zwykle funkcja wejściowa netto na jednostkę po prostu zsumować sygnałów na wejściu urządzenia otrzymuje się w określonym czasie (t).
Funkcja aktywacji konkretnej jednostki określa wewnętrzną aktywność jednostki, w zależności od wejścia netto (określonego przez funkcję wejścia netto), którą otrzymuje jednostka. Istnieje wiele różnych rodzajów funkcji aktywacyjnych, które mogą wykorzystywać poszczególne jednostki. „Typ” określonej jednostki zależy od jej funkcji aktywacji. Być może najprostszy rodzaj aktywacji jest zilustrowany poniżej,
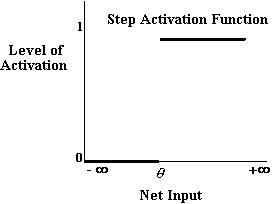
Rysunek 3-2
Funkcje aktywacyjne, takie jak ta, działają raczej jak przełączniki i czasami nazywane są „funkcjami krokowymi”. Jeśli dane wejściowe netto jednostki stosującej taką funkcję aktywacji są większe niż pewna wartość progowa, q, urządzenie staje się w pełni aktywne.3 Jeśli wejście netto jest poniżej tego poziomu, jednostka przetwarzająca jest całkowicie nieaktywna. Funkcja aktywacji, aj, dla takiej jednostki, j, można wyrazić bardziej formalnie w następujący sposób;
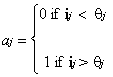
gdzie ij jest wejściem netto odebranym przez jednostkę w czasie t i qj jest wartością progową dla jednostki j.
Tego rodzaju funkcje aktywacyjne były używane w najwcześniejszych dniach badań sieci. Niestety, choć podlegają pewnym znaczącym ograniczeniom (patrz Minsky i Papert 1968). W szczególności nie jest możliwe szkolenie sieci, które stosują tego rodzaju jednostki rozmieszczone w więcej niż dwóch warstwach.
Obecnie, w dziedzinie sieci nadających się do szkolenia, zdecydowanie najpowszechniejszym rodzajem jednostki przetwarzania stosowanej przez łączników jest to, co Ballard (1986) nazwał „urządzeniem integracyjnym”. Funkcja logistyczna opisana na przykład przez Rumelharta i in. (1986a: str. 324-325) jest instancją urządzenia integracyjnego. Urządzenia integracyjne mają funkcję aktywacji sigmoidalnej, podobną do tej zilustrowanej poniżej, i można je opisać jako ciągłe przybliżenie funkcji skokowej.
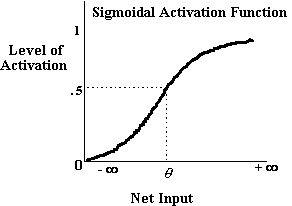
Rysunek 3-3
Funkcja aktywacji, aj, dla jednostki, j, tej odmiany, otrzymując dane wejściowe netto ij jest;
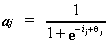
Urządzenia integracyjne zawierają w swojej funkcji aktywacji coś, co nazywa się „uprzedzeniem”. Odchylenie służy do zmiany poziomu wejścia do jednostki, która jest potrzebna do aktywacji tej jednostki, a zatem jest analogiczna do progu funkcji skokowej. W bardziej technicznym ujęciu odchylenie służy do tłumaczenia funkcji aktywacji wzdłuż osi reprezentującej wejście netto, zmieniając w ten sposób położenie funkcji aktywacji w przestrzeni wejściowej netto. j termin w równaniu logistycznym to termin odchylenia tej funkcji aktywacji.
Ważną cechą sigmoidalnych funkcji aktywacji jest to, że są one różniczkowalne. Jest to ważne, ponieważ umożliwia trenowanie sieci z więcej niż dwiema warstwami jednostek przetwarzania, wykorzystując potężne zasady uczenia się, takie jak uogólniona reguła delta, opisana przez Rumelharta, Hintona i Williamsa (1986a: s. 322-328). Ta zdolność do szkolenia sieci z wieloma warstwami znacznie zwiększyła moc sieci.
Chociaż jednostki urządzeń integracyjnych są prawdopodobnie najczęściej stosowanym typem jednostki w sieciach nadających się do trenowania w chwili obecnej, zbadano również inne funkcje aktywacji. Ostatnio Dawson i Schopflocher (1992) opisali rodzaj jednostki przetwarzania, którą nazywają, zgodnie z terminologią Ballarda (1986), „jednostką wartości”. Jednostki wartości wykorzystują funkcję aktywacji Gaussa, taką jak ta poniżej,
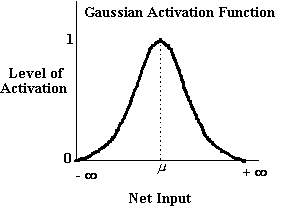
Rysunek 3-4
Funkcja aktywacji, aj, dla jednostki, j, tej odmiany, otrzymując dane wejściowe netto ij jest;
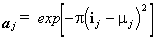
Jako dane wejściowe netto, ij, do jednostki wartości wzrasta, poziom aktywacji jednostki, aj, wzrasta, ale tylko do pewnego momentu, j. Gdy ij = j, aktywacja aj jest zmaksymalizowany i ma wartość 1. Jeśli jednostka otrzyma wkład netto większy niż j, aktywacja jednostki zaczyna się ponownie zmniejszać, aż do 0. W konsekwencji posiadania tego rodzaju funkcji aktywacji, jednostki wartości będą generować tylko silną aktywację dla wąskiego zakresu wejść netto. Jednostki wartości, takie jak urządzenia integracyjne, mogą być używane do konstruowania nadających się do szkolenia sieci wielowarstwowych.
Jednostka w sieci koneksjonistyczne zazwyczaj wysyła sygnał do innych jednostek w sieci lub poza siecią. Sygnał, że jednostka wysyła zależy od funkcji wyjścia. Funkcja wyświetlania zależy od stanu aktywacji urządzenia. Powszechną praktyką jest, w chwili obecnej, że funkcja wyjścia w danej jednostce jest taka, że po prostu wysyła sygnał do jego odpowiednika wartości aktywacji. Jednakże, nie ma powodu, dla którego teoretyczny koniecznie musi to być przypadek.
Modyfikowalne połączenia
Aby konkretna sieć łącznikowa przetwarzała informacje, jednostki w sieci muszą być połączone ze sobą. Dzięki tym połączeniom jednostki komunikują się ze sobą. Połączenia w sieci są zwykle „ważone”. Waga połączenia określa ilość sygnału wejściowego do połączenia, które zostanie przekazane między jednostkami. Wagi połączeń (czasami nazywane również „mocami połączenia”) są dodatnimi lub ujemnymi rzeczywistymi wartościami liczbowymi. Ilość danych wejściowych dostarczanych przez dane połączenie do jednostki, z którą jest połączony, jest wartością wyniku funkcji wyjściowej jednostki wysyłającej pomnożoną przez wagę połączenia.
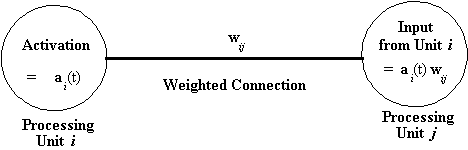
Rysunek 3-5
Zasadniczo nie ma ograniczeń co do liczby lub wzorca połączeń, które może mieć dana jednostka. Jednostki mogą mieć ze sobą ważone połączenia, a nawet mogą istnieć pętle lub cykle połączeń. Jednak dla obecnych celów nie ma potrzeby badania takich złożoności. Zamiast tego uwaga zostanie ograniczona do prostych systemów trójwarstwowych, takich jak ten przedstawiony poniżej.
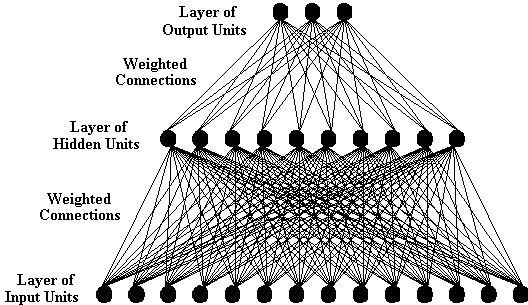
Rysunek 3-6
Jeśli poszczególne jednostki przetwarzania danych w systemie można otrzymać ze źródeł zewnętrznych wejść do samej sieci, urządzenia te są zwykle nazywane jednostek wejściowych. Ewentualnie, jeśli poszczególne jednostki przetwarzające może wysyłać sygnały na zewnątrz samej sieci, urządzenia te są zwykle nazywane jednostki wyjściowe. Wreszcie, tylko jednostki, które mogą bezpośrednio komunikować się z innymi urządzeniami w sieci (czyli jednostek, które nie mają bezpośredniego wejść i wyjść, które są zewnętrzne w stosunku do sieci) przetwarzanie są zwykle nazywane ukryte jednostki, Warstw ukrytych jednostek nie są istotną cechą sieci, chociaż wiele sieci wymaga pojedynczej warstwy ukryte jednostki do rozwiązywania szczególnych problemów. Jest też tak, że nie ma powodu, dla którego sieć powinna mieć tylko jedną warstwę ukrytych jednostek. Na przykład, sieć opisany Bechtel i Abrahamsena (1991: str. 169) składa się z dwóch warstw jednostek ukrytych.
Zasady uczenia się
Reguła uczenia się to algorytm, którego można użyć do zmiany mocnych stron połączeń między jednostkami przetwarzającymi. Podczas gdy wszystkie systemy łącznikowe mają jednostki przetwarzania i wzorce połączeń między jednostkami, nie wszystkie systemy mają reguły uczenia się. Niektóre sieci (np. Interaktywna sieć aktywacji i konkurencji Jets and Sharks, opisane w McClelland i Rumelhart (1988)) są tworzone ręcznie (lub „kodowane ręcznie”). Sieci kodowane ręcznie mają wagi połączeń między jednostkami przetwarzającymi ustawionymi ręcznie przez program budujący sieć. Jednak w większości sieci łącznikowych stosowana jest pewna zasada uczenia się. W tej rozprawie zajmę się przede wszystkim sieciami stosującymi zasady uczenia się.
Reguła uczenia się jest używana do modyfikowania wag połączeń w sieci, tak aby (miejmy nadzieję) uczynić sieć lepszym w stanie wytworzyć odpowiednią odpowiedź dla danego zestawu wejść. Sieci, które korzystają z reguł uczenia się, muszą przejść szkolenie, aby reguła uczenia się miała możliwość ustawiania wag połączeń. Szkolenie zazwyczaj polega na przedstawieniu sieci z wzorami reprezentującymi bodźce wejściowe w ich warstwie wejściowej. Powszechnie zdarza się, że ciężary połączeń są ustawiane losowo przed treningiem.
Na przykład rozważ jedną z najpopularniejszych reguł uczenia się dla sieci łącznikowych, uogólnioną regułę delta Rumelharta, Hintona i McClellanda (1986). Podczas korzystania z tej reguły sieć pokazuje przykładowe wzorce z zestawu treningowego. Celem uogólnionej reguły delta jest zmodyfikowanie wag połączeń sieci w taki sposób, aby sieć generowała pożądaną odpowiedź na każdy wzorzec w zestawie szkoleniowym.
Dokładniej rzecz ujmując, dzięki uogólnionym regułom delta nauka odbywa się poprzez przedstawienie jednego z wzorców z zestawu treningowego do warstwy wejściowej sieci. Powoduje to wysłanie sygnału do ukrytej warstwy (warstw), co z kolei powoduje wysłanie sygnału do warstwy wyjściowej. W uogólnionej regule delta rzeczywiste wartości aktywacji każdej jednostki wyjściowej są porównywane z wartościami aktywacji, które są pożądane dla wzorca wejściowego. Błąd dla każdej jednostki wyjściowej to różnica między jej aktywacją rzeczywistą a pożądaną. Uogólniona reguła delta używa tego terminu błędu do modyfikowania wag połączeń bezpośrednio podłączonych do jednostek wyjściowych. Błąd jest następnie wysyłany przez te zmodyfikowane wagi jako sygnał do ukrytych jednostek, które wykorzystują ten sygnał do obliczenia własnego błędu. Błąd obliczony na tym etapie jest następnie używany do modyfikowania wag połączeń między jednostkami wejściowymi i jednostkami ukrytymi. W każdym przypadku, gdy masa zostanie zmieniona, uogólniona reguła delta gwarantuje, że ta zmiana zmniejszy błąd sieci do bieżącego wzorca wejściowego.
Zazwyczaj reguła uczenia się wprowadza niewielkie zmiany w wagach połączeń między warstwami przy każdym zastosowaniu. W rezultacie szkolenie często wymaga licznych prezentacji zestawu wzorców wejściowych. Dzięki wielokrotnemu przedstawianiu zestawu szkoleniowego i zastosowaniu reguły uczenia się, sieci mogą nauczyć się tworzyć prawidłowe odpowiedzi na zestaw danych wejściowych, które składają się na zestaw treningowy. Reguły uczenia się oferują zatem sposób tworzenia sieci z odwzorowaniami wejścia/wyjścia odpowiednimi do konkretnych zadań lub problemów. Każda prezentacja zestawu wzorców wejściowych i wzorców wyjściowych jest znana jako „epoka” lub „przemiatanie”. Gdy sieć wytwarza dane wyjściowe dla każdego wzorca wejściowego, który jest wystarczająco blisko (jak określił eksperymentator) do żądanego wyjścia dla każdego wzorca, szkolenie zatrzymuje się i mówi się, że sieć ma „zbieżność”.
- 1) Chociaż zwyczajowo używane terminy „koneksjonistyczne” i „PDP” skutecznie się synonimy, te dwa terminy, gdy mają różne znaczenie. Początkowo tak zwane modele „koneksjonistyczne” były na ogół związane z pracą Ballarda na University of Rochester. Tak zwane modele „PDP”, z drugiej strony, były związane z badaniami grupy PDP San Diego (więcej szczegółów na temat etymologii tych warunków, zobacz Smolensky 1991: s. 225, przypis 5.). Będę śledzić to, co jest teraz obecna praktyka i użyć dwie kadencje jako synonimy.
- 2) Termin „netto” tutaj nie jest przeznaczona jako skrót terminu „sieć”. Zamierzony poczucie jest to, że „netto” w przeciwieństwie do „brutto”.
- 3) Należy zauważyć, że poziom aktywacji nie musi być 0 i 1. Wartości te są stosowane tylko dla celów poglądowych.
Godny uwagi. Naciśnij przycisk „Wstecz” w przeglądarce, aby powrócić do swojego miejsca w tekście.
Ta strona została zaprojektowana i utrzymywana przez Istvána SN Berkeley filozofii Programu w USL. Proszę kierować wszystkie komentarze i pytania do [email protected] Ta strona ostatniej aktualizacji: 27 sierpnia 1997. Logo projektu przez Leslie Schilling z Resource Center humanistycznych w USL.